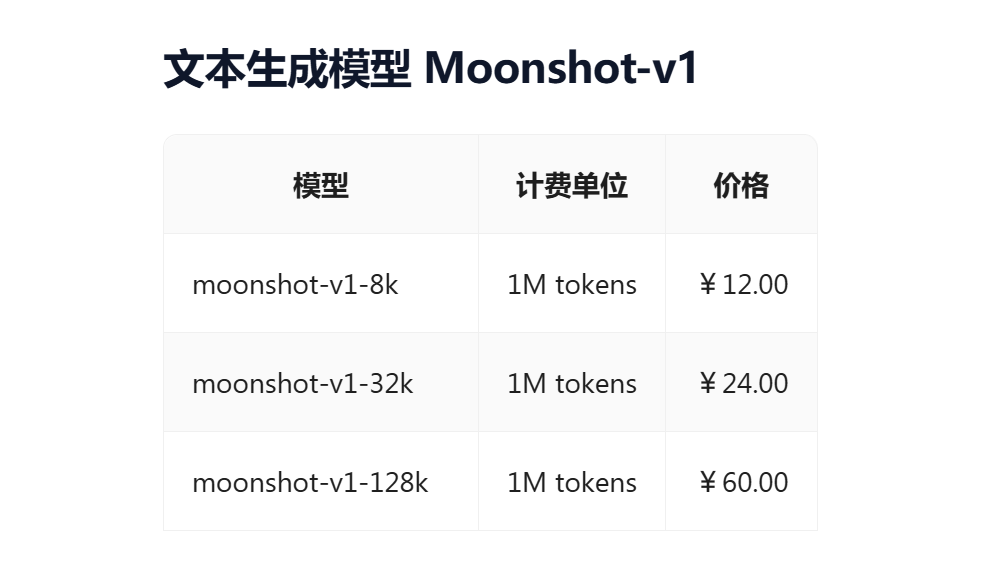
通过调用月之暗面API实现解析文档

基于MOONSHOT AI的api,我们可以用它来做许多事情,例如:
1、自然语言处理(NLP)
应用于例如客服系统:分析用户提问,匹配最优答案。智能写作工具:如文章摘要、生成邮件或报告等
2、图像处理与计算机视觉
图像分类、目标检测、利用生成对抗网络(GAN),生成艺术风格图片,修复图像,去除背景、OCR(光学字符识别)、在图像中检测并识别人脸,验证身份等
3、数据分析与预测
例如工业或金融上的预测模型、聚类与推荐系统、异常检测等
还有许多功能这里不一一赘述。在这里我们使用MOONSHOT AI来处理上传表单,并解析成JSON文本。使用这个JSON文本更新ErpNext里的表单以及子表。以下是官方的API文档以及示例代码
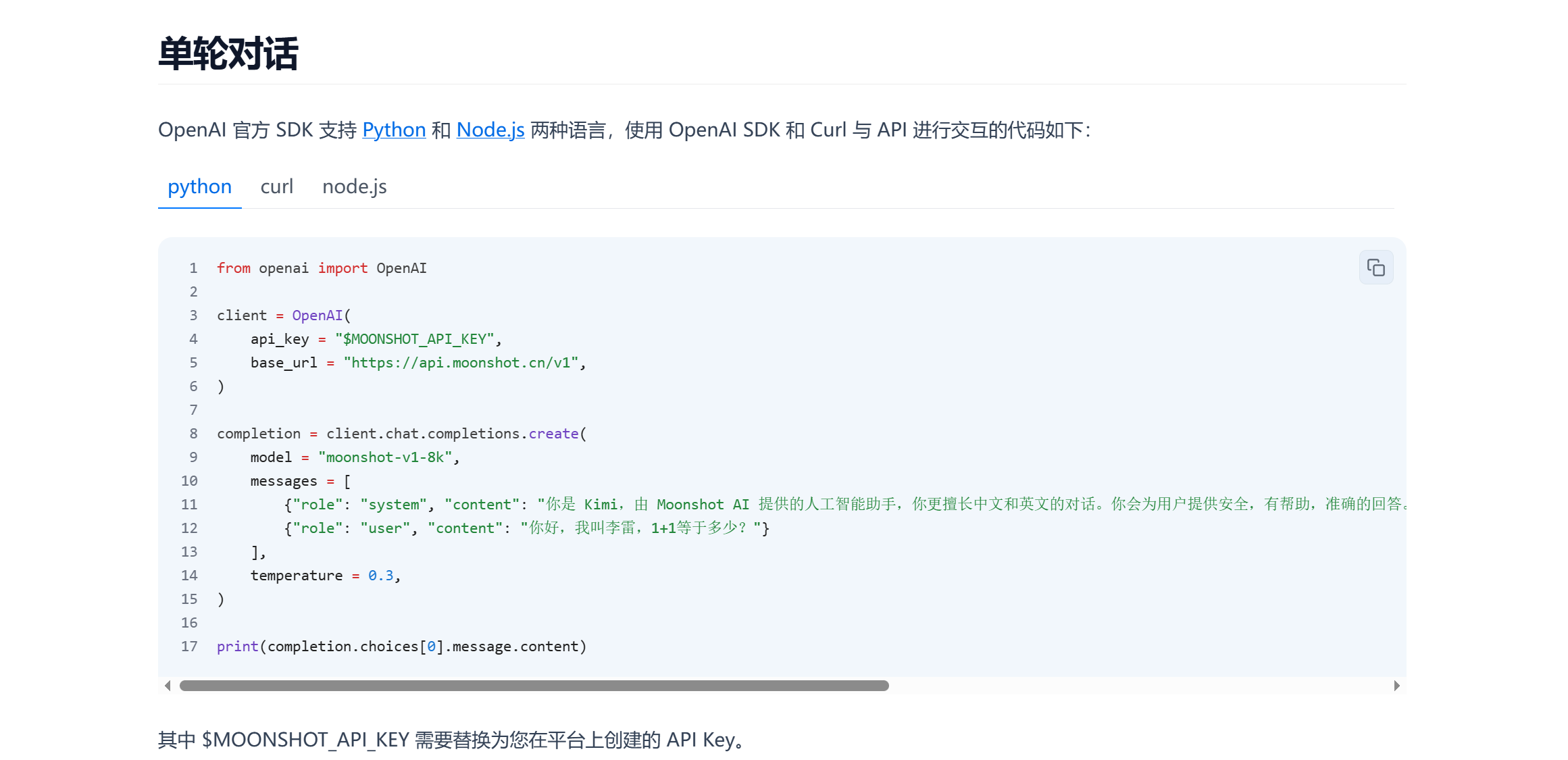
文件接口 - Moonshot AI 开放平台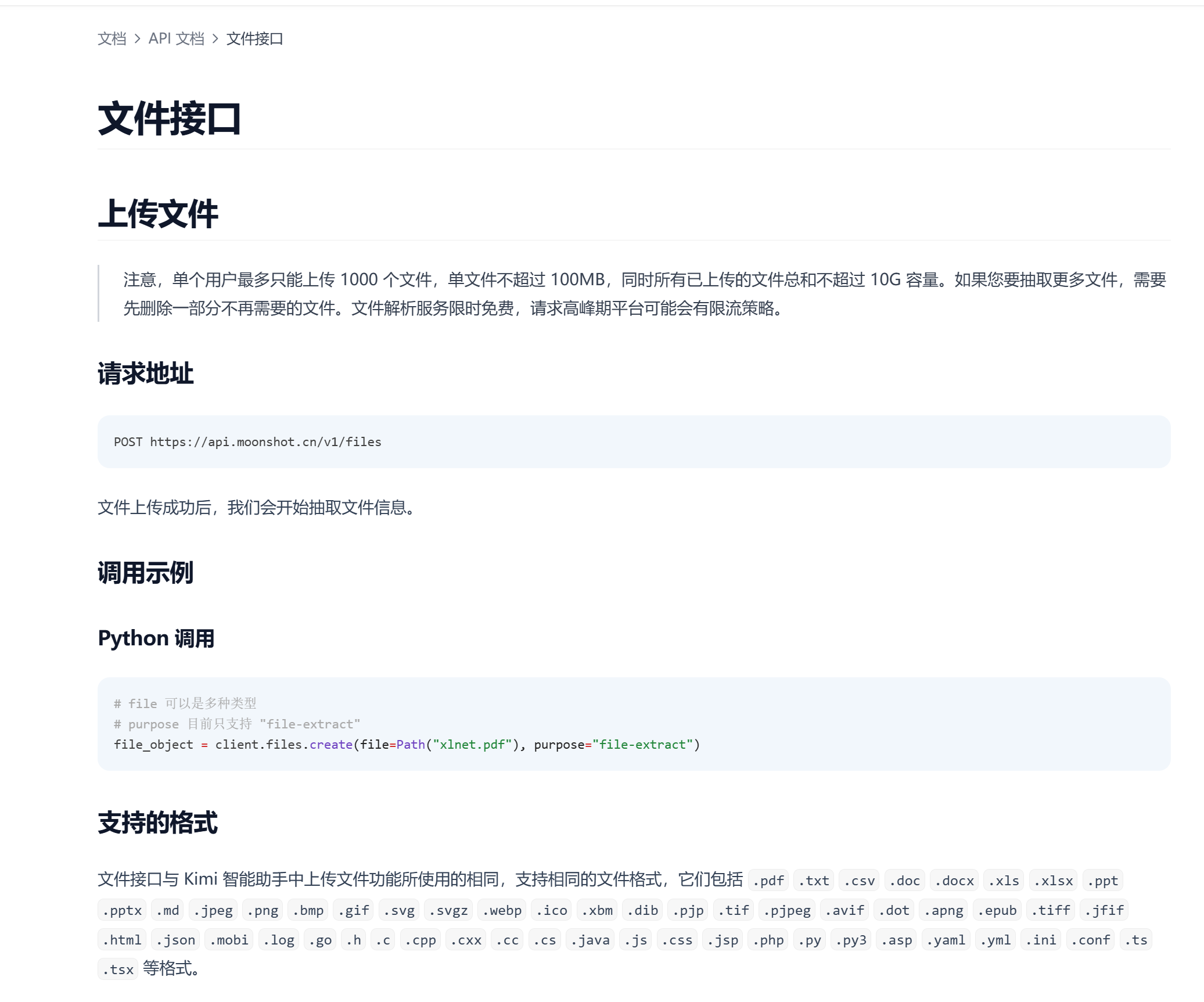
from pathlib import Path
from openai import OpenAI
client = OpenAI(
api_key = "$MOONSHOT_API_KEY",
base_url = "https://api.moonshot.cn/v1",
)
# xlnet.pdf 是一个示例文件, 我们支持 pdf, doc 以及图片等格式, 对于图片和 pdf 文件,提供 ocr 相关能力
file_object = client.files.create(file=Path("xlnet.pdf"), purpose="file-extract")
# 获取结果
# file_content = client.files.retrieve_content(file_id=file_object.id)
# 注意,之前 retrieve_content api 在最新版本标记了 warning, 可以用下面这行代替
# 如果是旧版本,可以用 retrieve_content
file_content = client.files.content(file_id=file_object.id).text
# 把它放进请求中
messages = [
{
"role": "system",
"content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。",
},
{
"role": "system",
"content": file_content,
},
{"role": "user", "content": "请简单介绍 xlnet.pdf 讲了啥"},
]
# 然后调用 chat-completion, 获取 Kimi 的回答
completion = client.chat.completions.create(
model="moonshot-v1-32k",
messages=messages,
temperature=0.3,
)
print(completion.choices[0].message)现在,我们正式开始说明讲解Agent Assistant
首先我们定义了一个函数get_json_data_from_freight_booking,文件的路径作为形参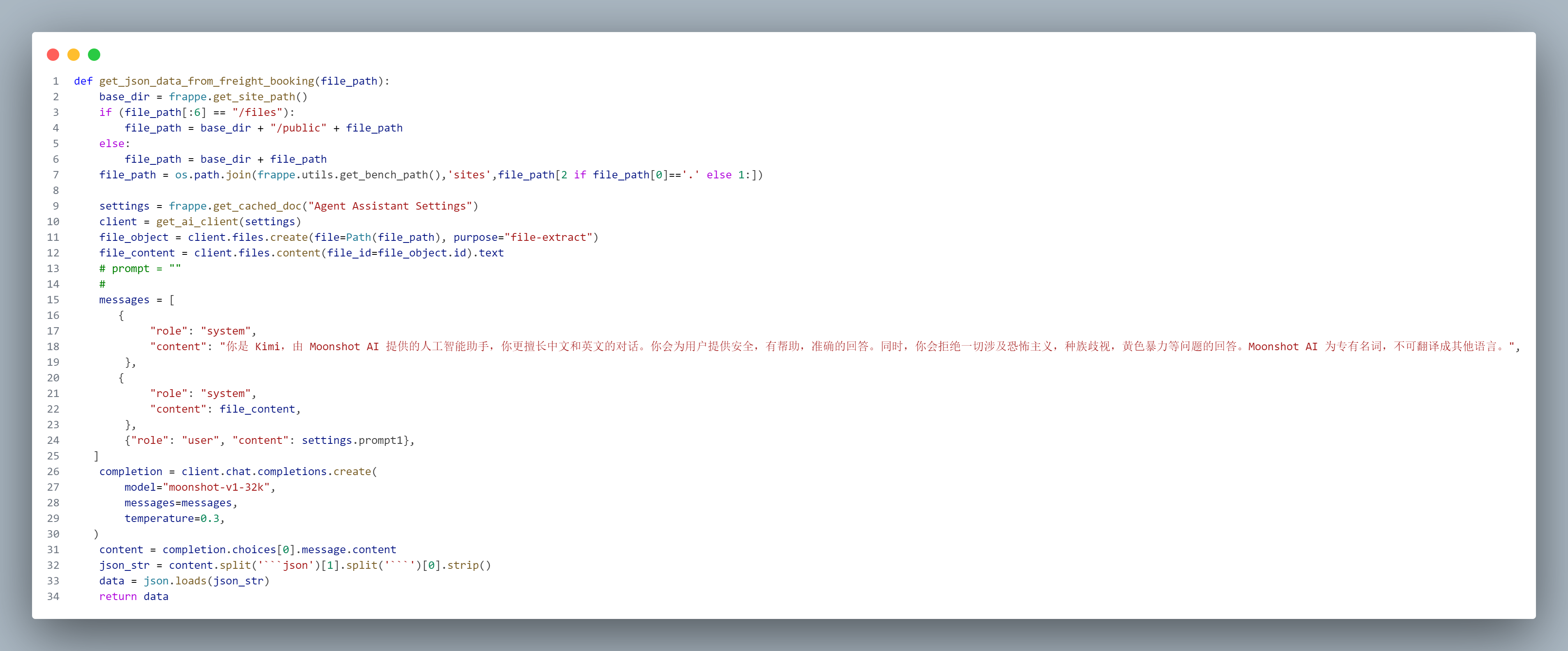
在第11行中调用了 client.files.create 方法来上传一个文件。这个方法需要两个参数:一个是 file,它是通过 Path(file_path) 创建的路径对象,另一个是 purpose,在这里被设置为 "file-extract",表示这个文件的用途是用于提取内容。
Path(file_path) 是一个 Path 类的实例,它代表了文件在文件系统中的路径。这个路径对象不仅可以存储文件路径,还提供了一些方法来进行文件操作,比如读取、写入等。
接下来,代码通过 client.files.content(file_id=file_object.id) 获取刚刚上传文件的内容。这里的 file_object.id 是上传后返回的文件对象的唯一标识符。调用 content 方法后,返回的内容被提取为文本格式,存储在 file_content 变量中。这一过程确保了文件的内容可以被后续的代码使用。
我们再从Frappe的缓存里拿到预设提示词的数据setting = frappe.get_cached_doc,提示词已经用一个实体初始设定好。把他放入msssages这个结构体里,就可以正式调用KIMI了。
最后get_json_data_from_freight_booking 会返回的是一个JSON
接着,我们调用这个函数
validate是Frappe里封装好的钩子函数,表示在表单执行前
我们调用get_json_data_from_freight_booking 这个函数,通过字典同步更新当前表单
完整代码:
# Copyright (c) 2024, yuxinyong and contributors
# For license information, please see license.txt
import os
import frappe
from frappe.model.document import Document
import json
from pathlib import Path
from openai import OpenAI
class FreightBooking(Document):
def validate(self):
self.parse_attachment()
def parse_attachment(self):
if self.attachment1 and not self.content1:
json_data = get_json_data_from_freight_booking(self.attachment1)
if json_data:
self.content1 = str(json_data)
self.update(json_data)
if self.attachment2 and not self.content2:
json_data = get_json_data_from_Arrival_Notification(self.attachment2)
if json_data:
self.content2 = str(json_data)
self.update(json_data)
if self.attachment3 and not self.content3:
json_data = get_json_data_from_Shipping_bill_message(self.attachment3)
if json_data:
self.content3 = str(json_data)
self.update(json_data)
for fee in json_data.get('fee', []):
if isinstance(fee, str):
fee = {'fee_list': fee}
self.append('ship_bill_details', {
'fee_list': fee.get('fee_list'),
'description': fee.get('description'),
'curr': fee.get('curr'),
'qty': fee.get('qty'),
'price': fee.get('price'),
'amount' : fee.get('price') * fee.get('qty')
})
def get_json_data_from_freight_booking(file_path):
base_dir = frappe.get_site_path()
if (file_path[:6] == "/files"):
file_path = base_dir + "/public" + file_path
else:
file_path = base_dir + file_path
file_path = os.path.join(frappe.utils.get_bench_path(),'sites',file_path[2 if file_path[0]=='.' else 1:])
settings = frappe.get_cached_doc("Agent Assistant Settings")
client = get_ai_client(settings)
file_object = client.files.create(file=Path(file_path), purpose="file-extract")
file_content = client.files.content(file_id=file_object.id).text
# prompt = ""
#
messages = [
{
"role": "system",
"content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。",
},
{
"role": "system",
"content": file_content, # <-- 这里,我们将抽取后的文件内容(注意是文件内容,而不是文件 ID)放置在请求中
},
{"role": "user", "content": settings.prompt1},
]
completion = client.chat.completions.create(
model="moonshot-v1-32k",
messages=messages,
temperature=0.3,
)
content = completion.choices[0].message.content
json_str = content.split('```json')[1].split('```')[0].strip()
data = json.loads(json_str)
return data
def get_json_data_from_Arrival_Notification(file_path):
base_dir = frappe.get_site_path()
if (file_path[:6] == "/files"):
file_path = base_dir + "/public" + file_path
else:
file_path = base_dir + file_path
file_path = os.path.join(frappe.utils.get_bench_path(),'sites',file_path[2 if file_path[0]=='.' else 1:])
settings = frappe.get_cached_doc("Agent Assistant Settings")
client = get_ai_client(settings)
file_object = client.files.create(file=Path(file_path), purpose="file-extract")
file_content = client.files.content(file_id=file_object.id).text
# prompt = ""
#
messages = [
{
"role": "system",
"content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。",
},
{
"role": "system",
"content": file_content, # <-- 这里,我们将抽取后的文件内容(注意是文件内容,而不是文件 ID)放置在请求中
},
{"role": "user", "content": settings.prompt2},
]
completion = client.chat.completions.create(
model="moonshot-v1-32k",
messages=messages,
temperature=0.3,
)
content = completion.choices[0].message.content
try:
json_str = content.split('```json')[1].split('```')[0].strip()
data = json.loads(json_str)
except (IndexError, json.JSONDecodeError) as e:
print(f"Error parsing JSON: {e}")
print(f"Raw AI response: {content}")
data = {} # or handle the error as needed
return data
def get_json_data_from_Shipping_bill_message(file_path):
base_dir = frappe.get_site_path()
if (file_path[:6] == "/files"):
file_path = base_dir + "/public" + file_path
else:
file_path = base_dir + file_path
file_path = os.path.join(frappe.utils.get_bench_path(),'sites',file_path[2 if file_path[0]=='.' else 1:])
settings = frappe.get_cached_doc("Agent Assistant Settings")
client = get_ai_client(settings)
file_object = client.files.create(file=Path(file_path), purpose="file-extract")
file_content = client.files.content(file_id=file_object.id).text
# prompt = ""
#
messages = [
{
"role": "system",
"content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI 为专有名词,不可翻译成其他语言。",
},
{
"role": "system",
"content": file_content,
},
{"role": "user", "content": settings.prompt3},
# {"role": "user", "content": FreightBookingprompt},
]
completion = client.chat.completions.create(
model="moonshot-v1-32k",
messages=messages,
temperature=0.3,
max_tokens=30000,
)
content = completion.choices[0].message.content
print(content)
json_str = content.split('```json')[1].split('```')[0].strip()
data = json.loads(json_str)
return data
def get_ai_client(settings):
ai_api_key = settings.get_password("kimi_api_key")
client = OpenAI(api_key=ai_api_key, base_url="https://api.moonshot.cn/v1")
return client
注意:
如果你想要返回的内容很多,觉得Kimi API 返回的内容不完整、被截断或长度不符合预期。我的建议是先打印输出一下查看返回内容是否完整。
如果不完整可以调整max_token 的大小,如我在get_json_data_from_Shipping_bill_message 里设置max_token 为30000。
这时如果返回的内容还是不完整,就换个上下文长度更大的模型(模型的区别在于它们的最大上下文长度,这个长度包括了输入消息和生成的输出,在效果上并没有什么区别。)。并且通过 其它接口 - Moonshot AI 开放平台 接口计算输入内容的 Tokens 数量,随后使用 Kimi 大模型所支持的最大 Tokens 数量(例如,对于 moonshot-v1-32k 模型,它最大支持 32k Tokens)减去输入内容的 Tokens 数量,得到的值即是本次请求的 max_tokens 值。